



At Vannevar Labs, we use machine learning in various ways to extract insights from the data that we collect. To do this, we’re running inference with a suite of models as data flows into our system. To maintain regulatory compliance, we have to self-host all our models so that we can easily deploy to all environments that we will operate on, including government and air-gapped networks. We needed an online inference solution that could be hosted inside our network while also providing us with reliable, scalable infrastructure.
Ray was the ideal technology because it provides an extensible platform for us to build our ML serving infrastructure inside our network.
In this post, we go over:
- Vannevar Labs’ decision-making process in choosing Ray & Ray Serve over other alternatives.
- The technical benefits that Ray Serve provides for our ML model deployments.
- How we are deploying Ray Serve and our experiences working with Ray as a startup with more constrained engineering resources compared to larger adopters.
What kinds of applications are we running?
We operate multiple models that cater to diverse modalities including images, audio, and text. At the moment, we’re running more than 20 different models on the same real-time cluster. These models vary from small, lightweight classifiers to billion-parameter LLMs, running on millions of pieces of content per day. We’re constantly adding new models, so we need an infrastructure that’s flexible enough to onboard these models quickly.
Why Ray Serve?
We evaluated online inference solutions on the following criteria:
- Ability to self-host: Due to internal security requirements, all of our model deployments need to be deployed on air-gapped networks. This means the cluster where the models are deployed cannot access the external internet. To achieve this, we needed the ability to self-host whatever solution that we chose.
- Reliability & Adoption: We wanted a solution that has a large community behind it and that has been proven out for production workloads at other companies. Based on past experiences, having lots of users and an active community considerably helped developer velocity, allowing us to easily understand best practices and making debugging easier.
- Extensibility & future-proofing: While we are currently focused on online inference, we wanted a solution that can also easily extend to other workloads such as model training or offline inference. This allows us to scale up faster without creating additional infrastructure as we expand our ML workloads. LLM-related projects such as RayLLM were also interesting to us as we planned our upcoming work.
The ability to self-host eliminated most of the inference solutions available. It limited us to only open-source solutions.
This led us to evaluate the following as our primary options:
Cortex
- This was our existing ML inference platform. However, the open source project is no longer maintained after Databricks acquired the backing company.
- Cortex also required a lot of fine-tuning and was hard to configure. There wasn’t an active community which made working with Cortex difficult for our small engineering team.
BentoML
- BentoML is a solid up-and-coming inference platform, which has interesting batch and real-time inference solutions. However at the point when we tried it out, the project was still small, along with the community, which made it too risky for us to rely on.
- BentoML’s build strategy didn’t fit well with our more traditional CI/CD platform, because its requirements had to be installed on the machine building the Bento. By contrast, Ray installs the requirements remotely so this isn’t necessarily apart from non-pip/conda libraries.
Nvidia Triton
- Nvidia was very barebones, but has some neat features like different batching strategies and support for a single model and multi-node GPU usage.
- We found it too complicated; we needed something that was ready-to-go for our data scientists to deploy their machine learning models services.
- Nvidia was a single server solution, and we still needed to figure out some coordinated cluster/scaling on top of this.
Ray Serve
- Ray’s strength was its large community. We’ve already received help from the Ray community on Ray Slack.
- Ray has a proven track record at other companies, including Uber, Linkedin, OpenAI.
- Ray is extensible. Once we set up a Ray cluster for real-time inference with Ray Serve, we could use the same infrastructure setup and learnings to run scalable batch inference with Ray Data and model training with Ray Train.
Benefits of Ray Serve
Once we decided to further explore Ray Serve, we found it provided strong technical value during the POC process.
Multiple App Serving on a Single Cluster
With Ray Serve, we can deploy multiple models/applications on a single cluster. For real-time inference, this was a huge benefit because it lowers our overall maintenance overhead, reducing the burden on our smaller DevOps team.
Fractional GPU Allocation
Most of our models won’t saturate an entire GPU. With Ray Serve, we don’t need to allocate an entire GPU for each model replica, allowing us to save resources and maximize GPU utilization.
Ease of Deployment
Deployment of a new model on Ray is very straightforward. For example, here is the majority of the code that it took to deploy our Voice Activity Detection model on our Ray cluster:
### Deployment Configuration ###
@serve.deployment(
ray_actor_options={
"num_cpus": 1,
},
autoscaling_config={
"min_replicas": 1,
"initial_replicas": 5,
"max_replicas": 20,
"target_num_ongoing_requests_per_replica": 2,
},
)
class VADModel:
### Application Logic ###
def __init__(self):
import vad as vad_model
from vad.utils import download_file, process_timestamps
self.vad_model = vad_model
self.decode_audio = decode_audio
self.get_sum_timestamps = process_timestamps
async def __call__(self, starlette_request: Request) -> Dict:
try:
req_json = (await starlette_request.json())
storage_path = req_json['storage_path']
local_path = self.download_file(storage_path)
audio = self.decode_audio(local_path)
timestamps = self.vad_model.get_voice_timestamps(audio)
os.remove(local_path)
return self.get_sum_timestamps(timestamps)
except Exception as e:
logger.exception(e)
vad = VADModel.bind()
After this, it’s a couple of CLI commands that we’ve automated into a GitHub action that will send this new deployment to the cluster.
This is what our repo setup and GH action originally looked like. We were using the RayCluster CRD for Kubernetes. We built some custom tools to manage blue/green deployments of Ray clusters when there was an update that was made on the cluster level.
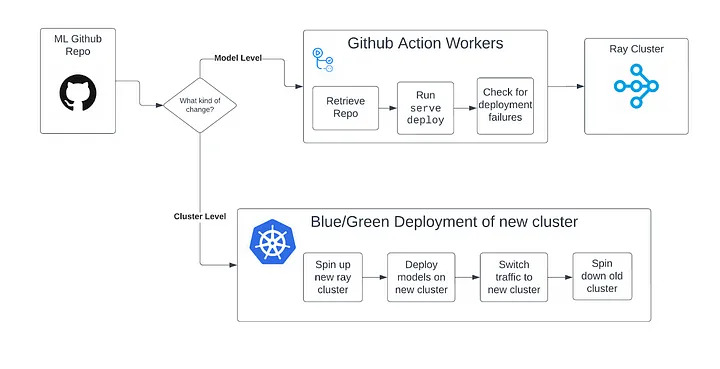
Once we upgraded to the RayService CRD, blue/green deployments were fully handled by Ray. So the above diagram turned into this:
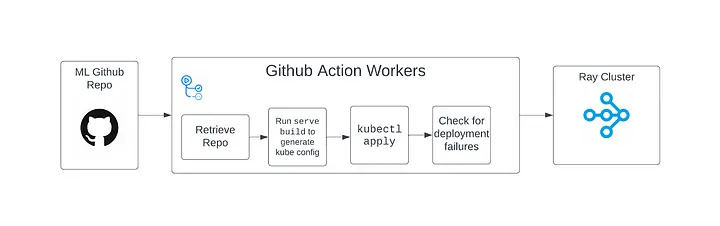
We only had to update the ray config in the RayService CRD using the same commands as we did previously, and Ray handles the rest.
Should you self-host a Ray Cluster?
We needed to get ML solutions deployed quickly but while being cost efficient and meeting compliance requirements: Ray was the right choice. Self-hosting Ray has allowed our startup to have full control over the deployment process and infrastructure, enabling us to tailor it to our specific needs and requirements. This level of customization has accelerated the deployment of ML solutions while also ensuring good performance and scalability.
Come join Vannevar Labs
We’re building cutting-edge products using bleeding-edge machine learning and data collection techniques to solve important DoD problems, and we need your help! Come check out our open roles!



